|
Currently, Meng Cao is a postdoctoral researcher at Mohamed bin Zayed University of Artificial Intelligence (MBZUAI), working with Prof. Xiaodan Liang and Prof. Ian D Reid. Prior to that, he worked as a researcher at International Digital Economy Academy (IDEA), supervised by Lei Zhang. He received the Ph.D. degree from School of Computer Science, Peking University, supervised by Prof. Yuexian Zou (2018 - 2023). He received his B.E. degree from Huazhong University of Science and Technology (2014 - 2018). During his Ph.D. period, he also worked closely with Prof. Mike Z. Shou from National University of Singapore, Prof. Long Chen from The Hong Kong University of Science and Technology, and Fangyun Wei from Microsoft Research Asia. His primary research interests are Computer Vision and Multimedia Analysis. He aims to build an interactive AI assistant that can not only ground and reason over multi-modal signals, but also assist humans in customized content creation.Email / CV / Google Scholar / Github |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
RAP: Efficient Text-Video Retrieval with Sparse-and-Correlated Adapter
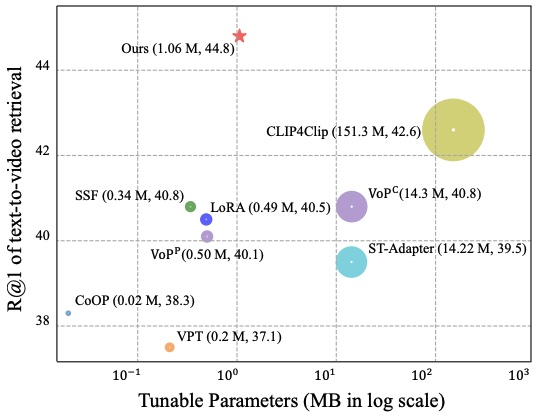
Meng Cao, Haoran Tang, Jinfa Huang, Peng Jin, Can Zhang, Ruyang Liu, Long Chen, Xiaodan Liang, Li Yuan, Ge Li Findings of the Association for Computational Linguistics, ACL 2024 Findings [Paperlink], [Code] Area: Text-Video Retrieval, Parameter-efficient Fine-tuning We propose RAP to conduct efficient text-video retrieval with a sparse-and-correlated adapter. |
|
Iterative Proposal Refinement for Weakly-Supervised Video Grounding
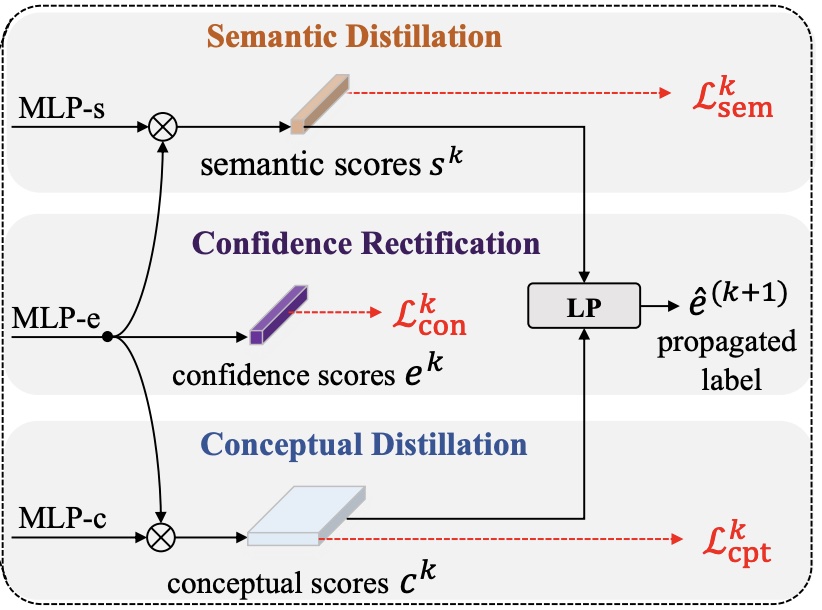
Meng Cao, Fangyun Wei, Can Xu, Xiubo Geng, Long Chen, Can Zhang, Yuexian Zou, Tao Shen, Daxin Jiang IEEE Computer Vision and Pattern Recognition Conference, CVPR 2023 [Paperlink], [Code] Area: Video Grounding, Weakly-Supervised Learning We introduce IRON, which includes a novel iterative proposal refinement module to model explicit correspondence for each proposal at both semantic and conceptual levels. |
|
LocVTP: Video-Text Pre-training for Temporal Localization
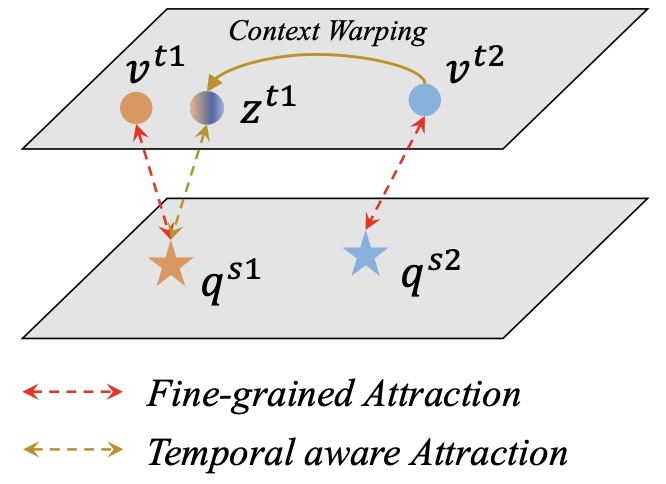
Meng Cao, Tianyu Yang, Junwu Weng, Can Zhang, Jue Wang, Yuexian Zou European Conference on Computer Vision, ECCV 2022 [Paperlink], [Code] Area: Video-Langauge Pre-training, Video Retrieval, Temporal Grounding We propose a novel Localization-oriented VideoText Pre-training framework, dubbed as LocVTP, which benefits both retrieval-based and the less-explored localization-based downstream tasks. |
|
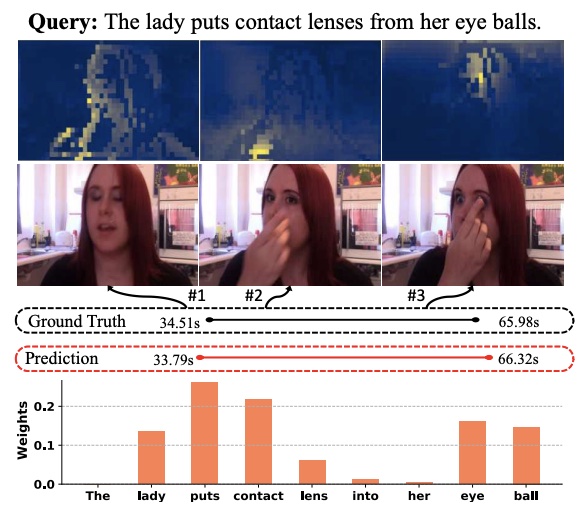
On Pursuit of Designing Multi-modal Transformer for Video Grounding Meng Cao, Long Chen, Mike Zheng Shou, Can Zhang, Yuexian Zou Empirical Methods in Natural Language Processing, EMNLP 2021 (Oral Presentation) [Paperlink], [Code] Area: Video Grounding, Transformer Architecture Design We propose the first end-to-end model GTR for video grounding, which is inherently efficient with extremely fast inference speed. Our comprehensive explorations and empirical results can help to guide the design of more multi-modal Transformerfamily models in other multi-modal tasks.. |

|
Correspondence Matters for Video Referring Expression Comprehension Meng Cao, Ji Jiang, Long Chen, Yuexian Zou ACM Multimedia, ACM MM 2022 [Paperlink], [Code] Area: Referring Expression Comprehension, Correspondence Modeling We propose a novel Dual Correspondence Network (dubbed as DCNet) which explicitly enhances the dense associations in both the inter-frame and cross-modal manners. |
|
Deep Motion Prior for Weakly-Supervised Temporal Action Localization Meng Cao, Can Zhang, Long Chen, Mike Zheng Shou, Yuexian Zou IEEE Transactions on Image Processing, TIP 2022 [Paperlink], [Code], [Video] Area: Temporal Action Localization, Weakly-Supervised Learning, Graph Network. We establish a context-dependent deep motion prior with a novel motion graph and propose an efficient motion-guided loss to inform the whole pipeline of more motion cues. |

|
UniFaceGAN: A UniFied Framework for Temporally Consistent Facial Video Editing Meng Cao, Haozhi Huang, Hao Wang, Xuan Wang, Li Shen, Sheng Wang, Linchao Bao, Zhifeng Li, Jiebo Luo IEEE Transactions on Image Processing, TIP 2021 [Paperlink], [Code], [Video] Area: Facial Video Manipulation, Generative Adversarial Network We present a unified framework that offers solutions for multiple tasks, including face swapping, face reenactment, and ``fully disentangled manipulation". |
|
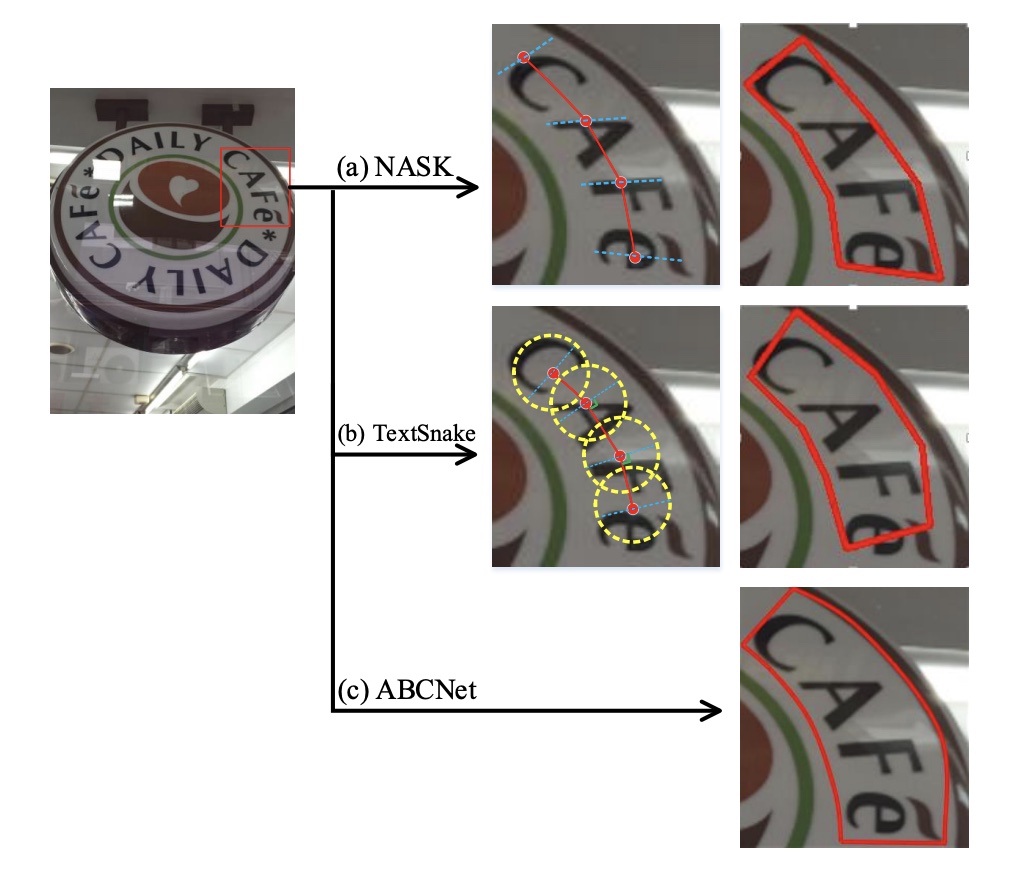
All You Need is a Second Look: Towards Arbitrary-Shaped Text Detection Meng Cao, Can Zhang, Dongming Yang, Yuexian Zou IEEE Transactions on Circuits and Systems for Video Technology, TCSVT 2021 [Paperlink] Area: Scene Text Detection We propose a two-stage segmentation-based scene text detector, which conducts the detection in a coarse-to-fine manner. Besides, we establish a much tighter representation for arbitrary-shapedtexts. |
|
Technical Report for WAIC Challenge of Financial QA under Market Volatility Meng Cao, Ji Jiang, Qichen Ye, Yuexian Zou Technical Report for TianChi Challenge [Paperlink] Winner of Financial QA Challenge We address the problem of financial QA by proposing a graph transformer model for the efficient multi-source information fusion. As a result, we won the first place out of 4278 participating teams and outperformed the second place by 5.07 times on BLUE. |
|
|
|
|
|
Last updated on Oct, 2023
This awesome template borrowed from this guy~
|